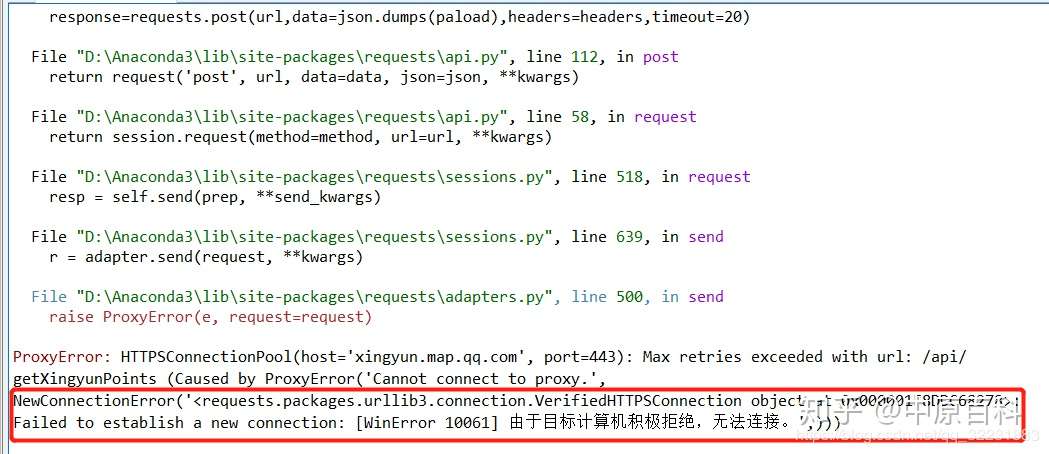
对于腾讯位置大数据平台,有一些商业接口可以调用
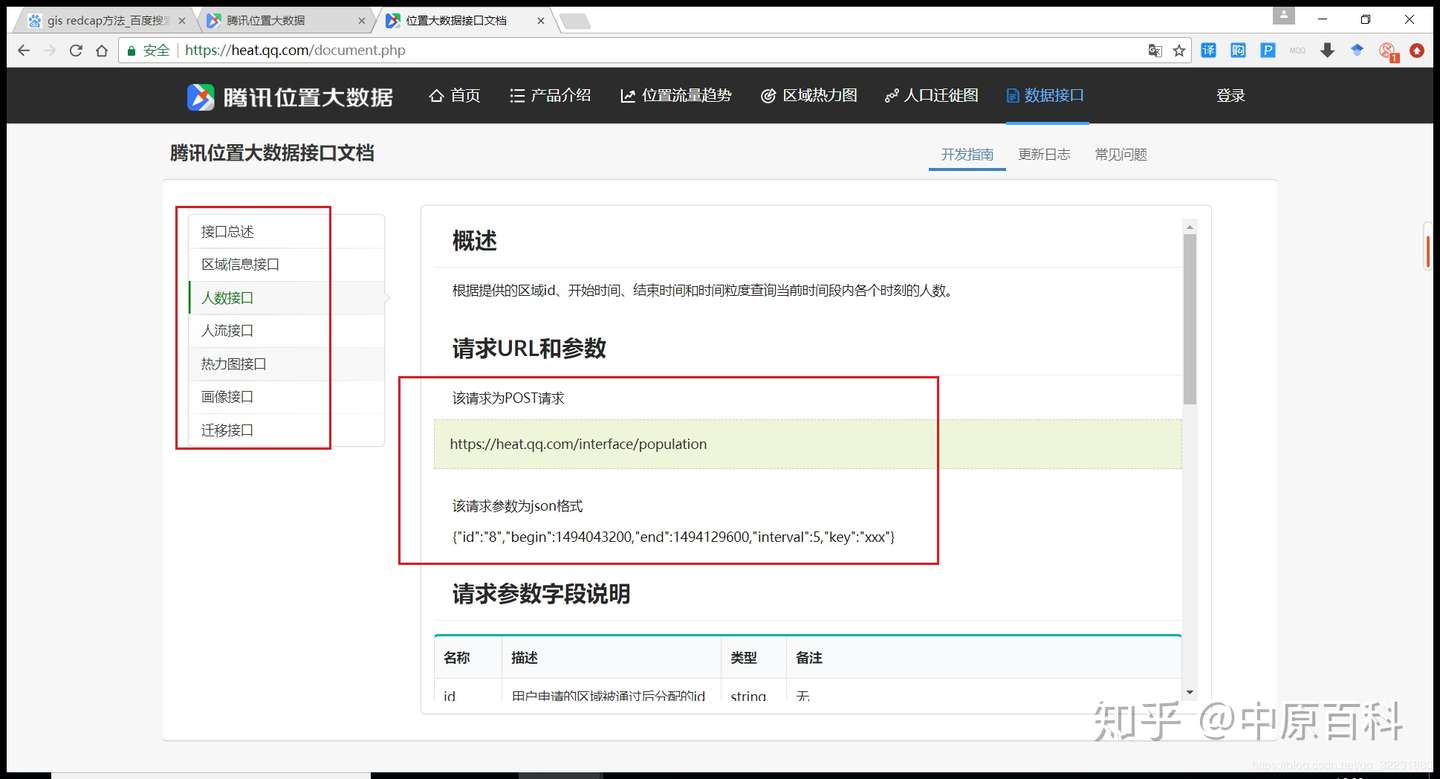
看起来还是挺爽的,但是现阶段只接受商业合作客户来调用,我们个人是获取不到的。
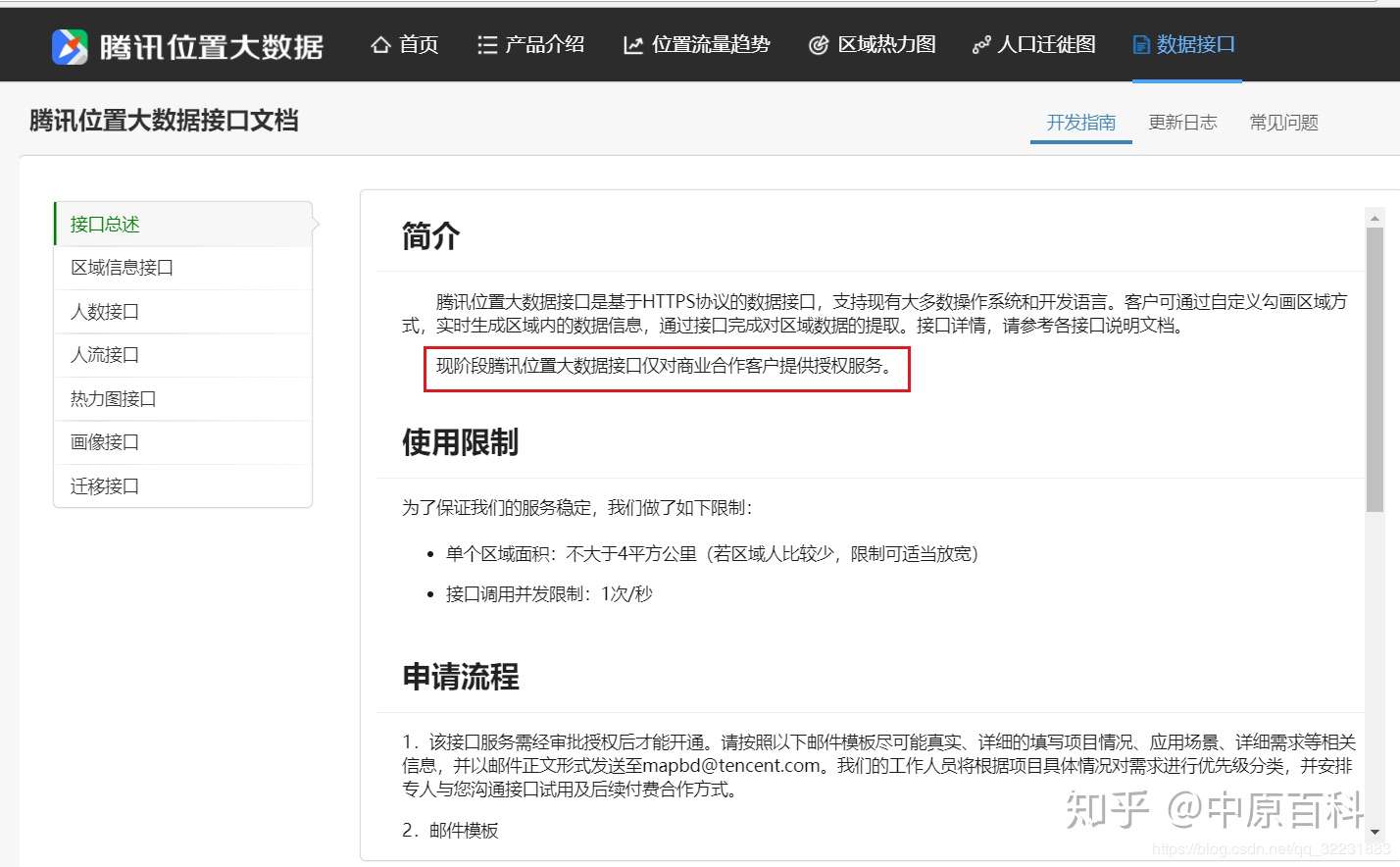
那就没办法了吗?当然不是,实际上腾讯位置大数据把调用接口就直接写在了前端,不过需要你花点心思去发现。
正文开始:
腾讯位置大数据平台网址如下https://heat.qq.com/
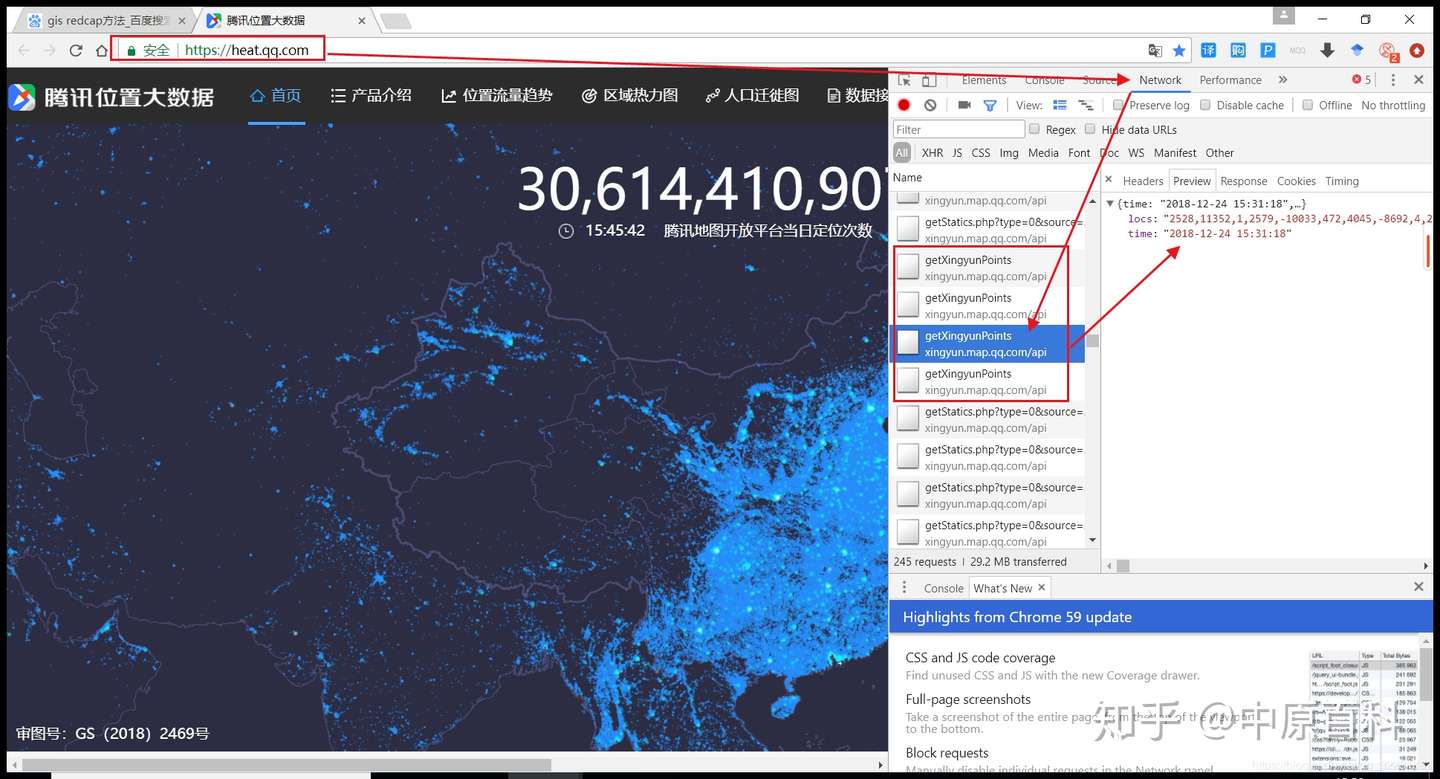
打开之后浏览器调到开发者模式开始抓包得到我们需要的定位数据。

如上图,这就是我们抓到的数据包,里面locs那一行中2528为北纬25.28度,11352则为东经113.52度,1则是在这一秒内该地点的定位次数。这一段数据量还是比较大的,如果你打开response来查看数据,浏览器能直接卡死,所以不得不说腾讯这个网页的前端做的实在太烂了。
我们再看腾讯位置大数据定位次数的更新频率,基本上隔一秒钟更新一次
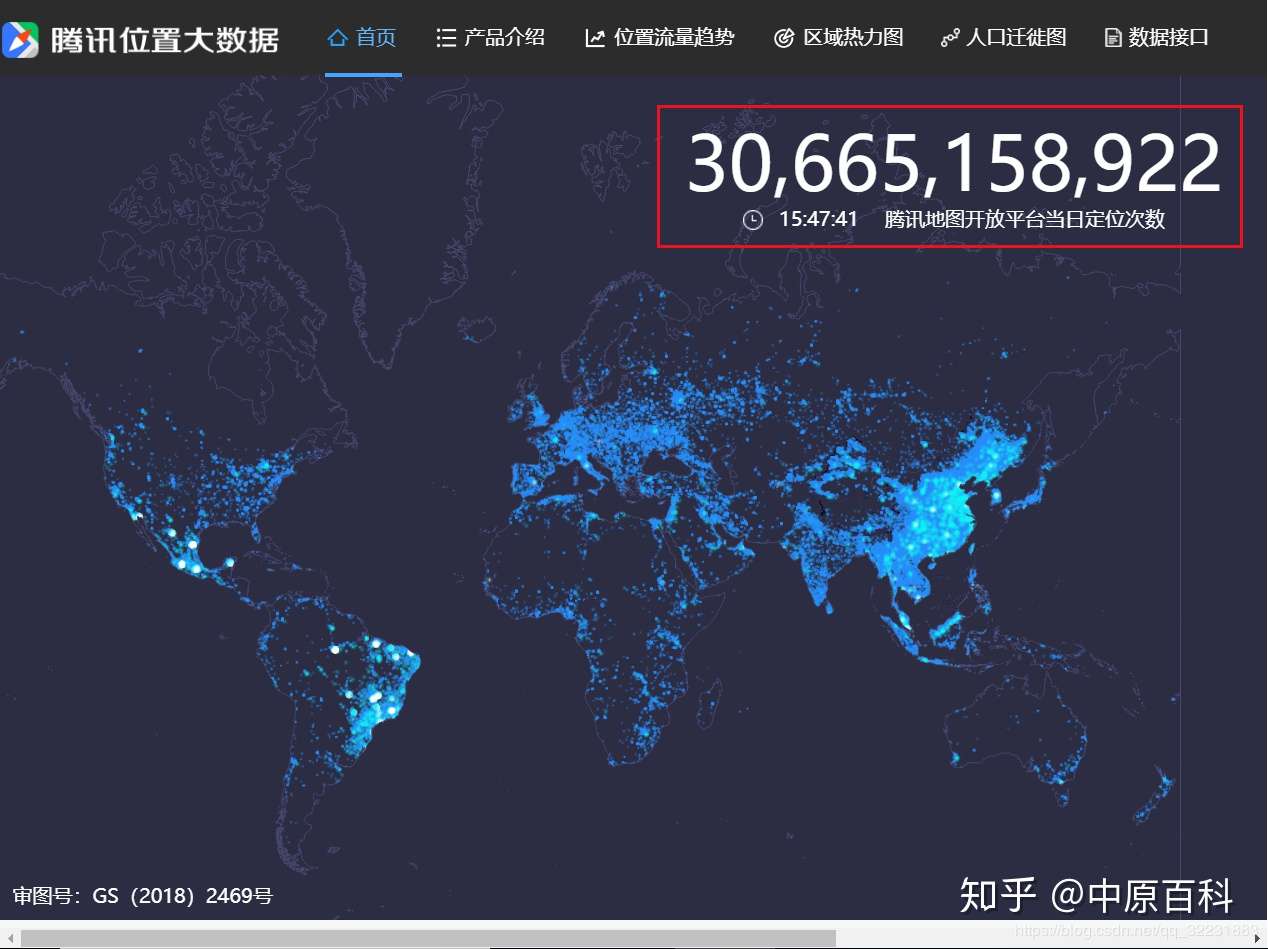
那我们就来抓一下这个每一次返回的数据,我们注意到getXingYunPoints这个链接每次更新出来都是四个链接,然后点击链接header可以查看到RequestPayload有两个参数。不断点击四个链接查看参数我们发现参数中count一直为4,而rank则分别为0、1、2、3 。
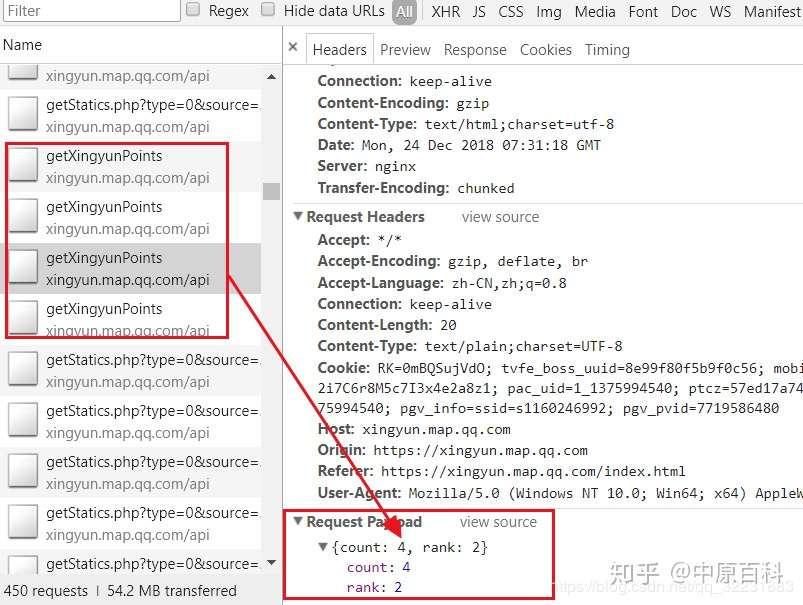
以上就是抓包分析的过程,分析完下面就简单了,通过爬虫可以抓取到如下数据:
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 8 00:45:20 2018
@author: 武状元
"""
import requests
import json
import pandas as pd
import time
def get_TecentData(count=4,rank=0): #先默认为从rank从0开始
url='https://xingyun.map.qq.com/api/getXingyunPoints'
locs=''
paload={'count':count,'rank':rank}
response=requests.post(url,data=json.dumps(paload))
datas=response.text
dictdatas=json.loads(datas)#dumps是将dict转化成str格式,loads是将str转化成dict格式
time=dictdatas["time"] #有了dict格式就可以根据关键字提取数据了,先提取时间
print(time)
locs=dictdatas["locs"] #再提取locs(这个需要进一步分析提取出经纬度和定位次数)
locss=locs.split(",")
#newloc=[locss[i:i+3] for i in range(0,len(locss),3)]
temp=[] #搞一个容器
for i in range(int(len(locss)/3)):
lat = locss[0+3*i] #得到纬度
lon = locss[1+3*i] #得到经度
count = locss[2+3*i]
temp.append([time,int(lat)/100,int(lon)/100,count]) #容器追加四个字段的数据:时间,纬度,经度和定位次数
result=pd.DataFrame(temp) #用到神器pandas,真好用
result.dropna() #去掉脏数据,相当于数据过滤了
result.columns = ['time', 'lat', 'lon','count']
result.to_csv('TecentData.txt',mode='a',index = False) #model="a",a的意思就是append,可以把得到的数据一直往TecentData.txt中追加
if __name__ =='__main__':
while(1): #一直循环吧,相信我,不到一小时你电脑硬盘就要炸,大概速度是一分钟一百兆数据就可以爬下来
for i in range(4):
get_TecentData(4,i) #主要是循环count,来获取四个链接里的数据
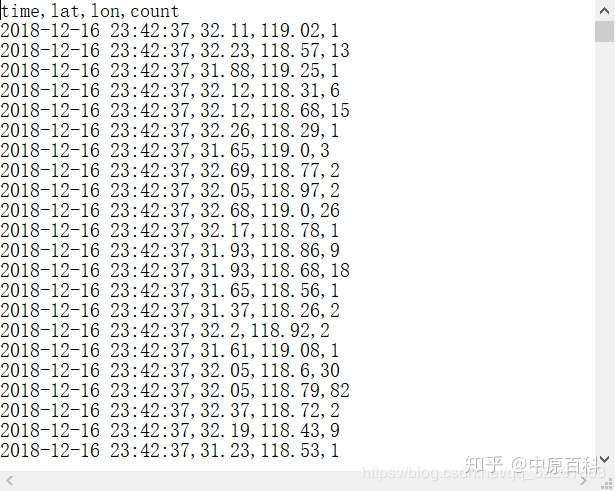
好了,这样就可以得到我们需要的数据了,以上是得到全球数据的办法。通过上述方法我获取了全球10天(100G左右)的腾讯位置大数据,还有2019年春节期间全国20天(80G左右)的腾讯位置大数据,这些数据可以用来研究人口分布特征和人口流动趋势等课题。但是如此大的数据怎么处理呢?一个txt文件100G,处理方法下一篇文章有简单介绍。
得到全球数据之后再进行数据清洗(比较繁琐)得到南京的数据,后面再导进ArcMap中就可以了。
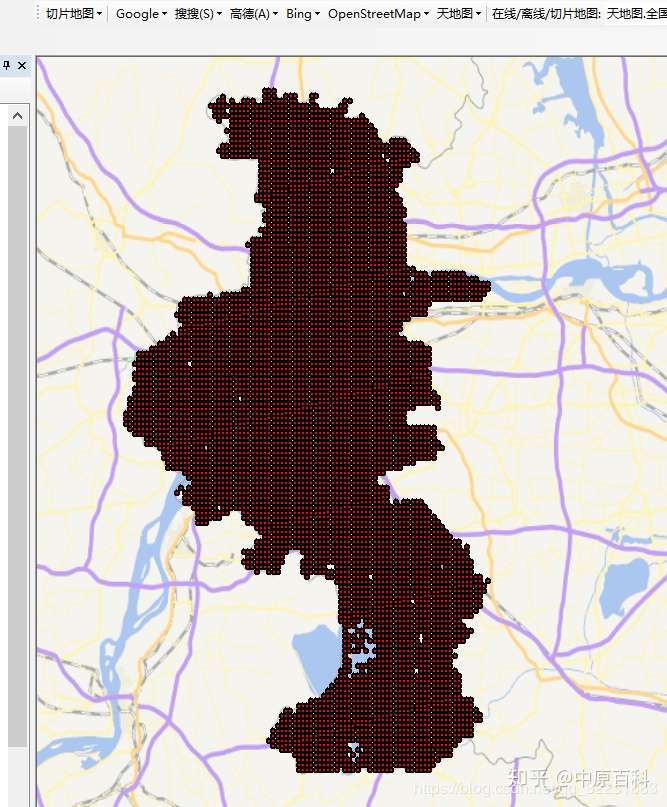
之后绘制渔网并自行建模,得到南京市1km*1km人口估算格网(详细过程以后会有专门文章讲解):
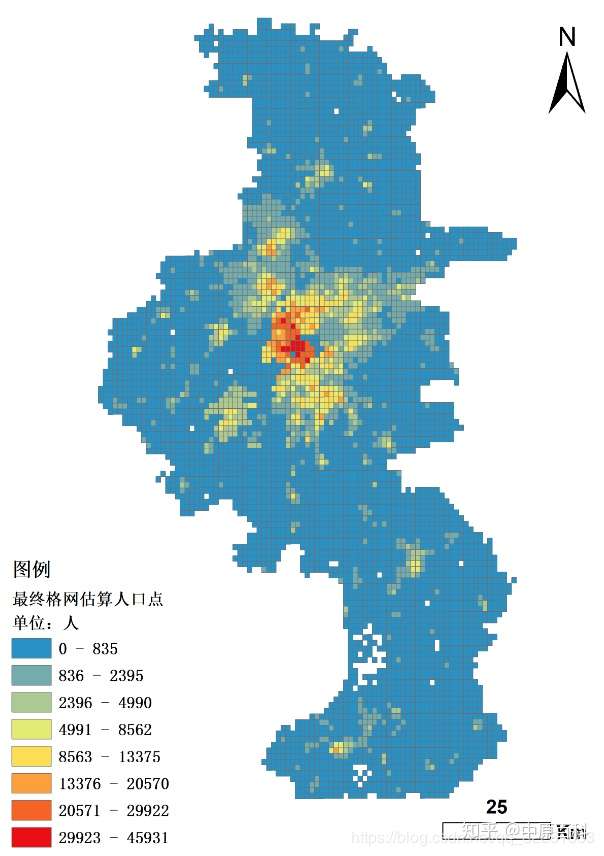
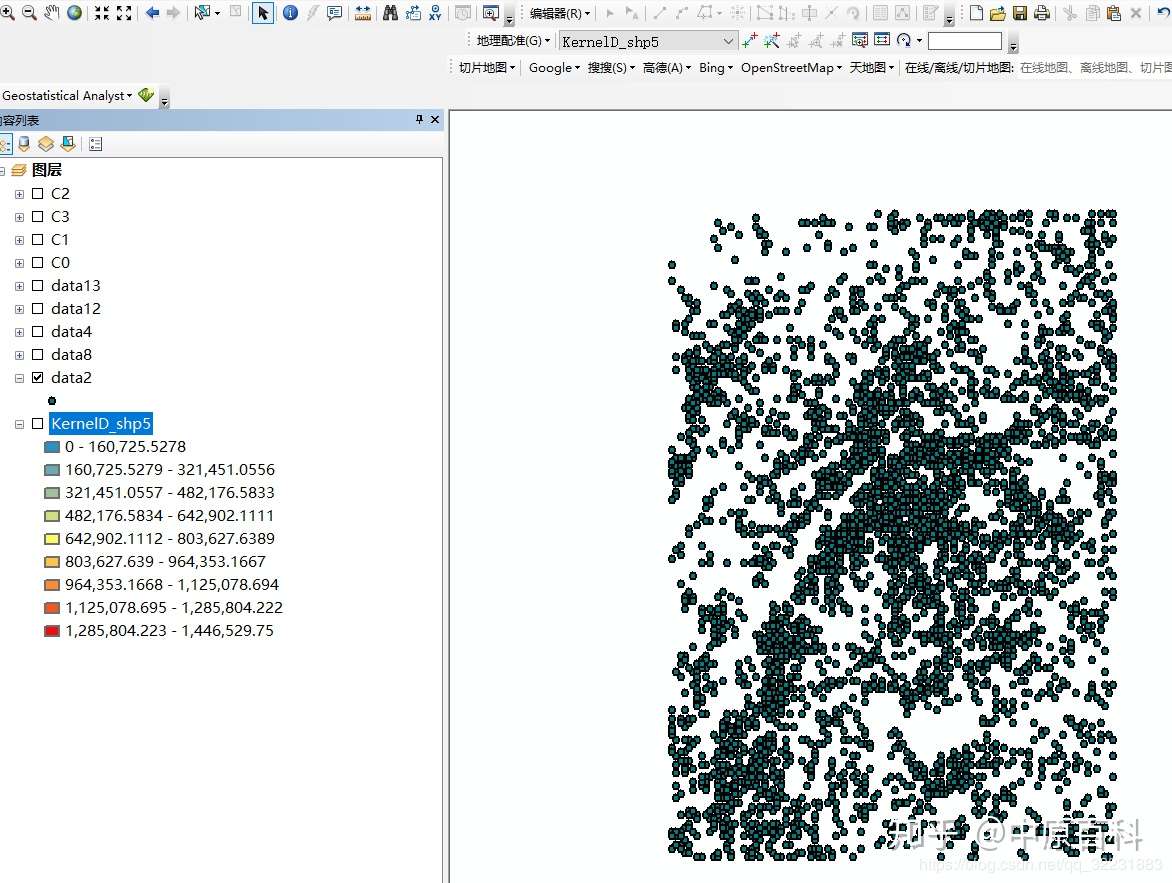
以上就是得到的数据,但是如果你真的就按照这个方法来很快你就会发现你电脑硬盘受不了了(原先我就是这么搞的,得到全球10天定位数据100多g),那怎样减少数据量呢?我发现了两个方法,一个从空间角度,一个从时间角度。
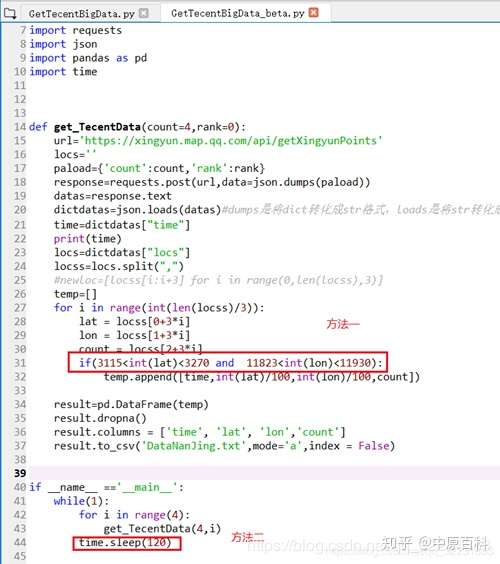
方法一:直接在抓数据的时候裁剪出 你需要的范围,比如南京的,纬度范围就是北纬31.15到北纬32.70,经度范围是东经118.23到东经119.30,于是乎一个if语句就解了。
if __name__ =='__main__':
while(1):
for i in range(4):
get_TecentData(4,i)
time.sleep(120)
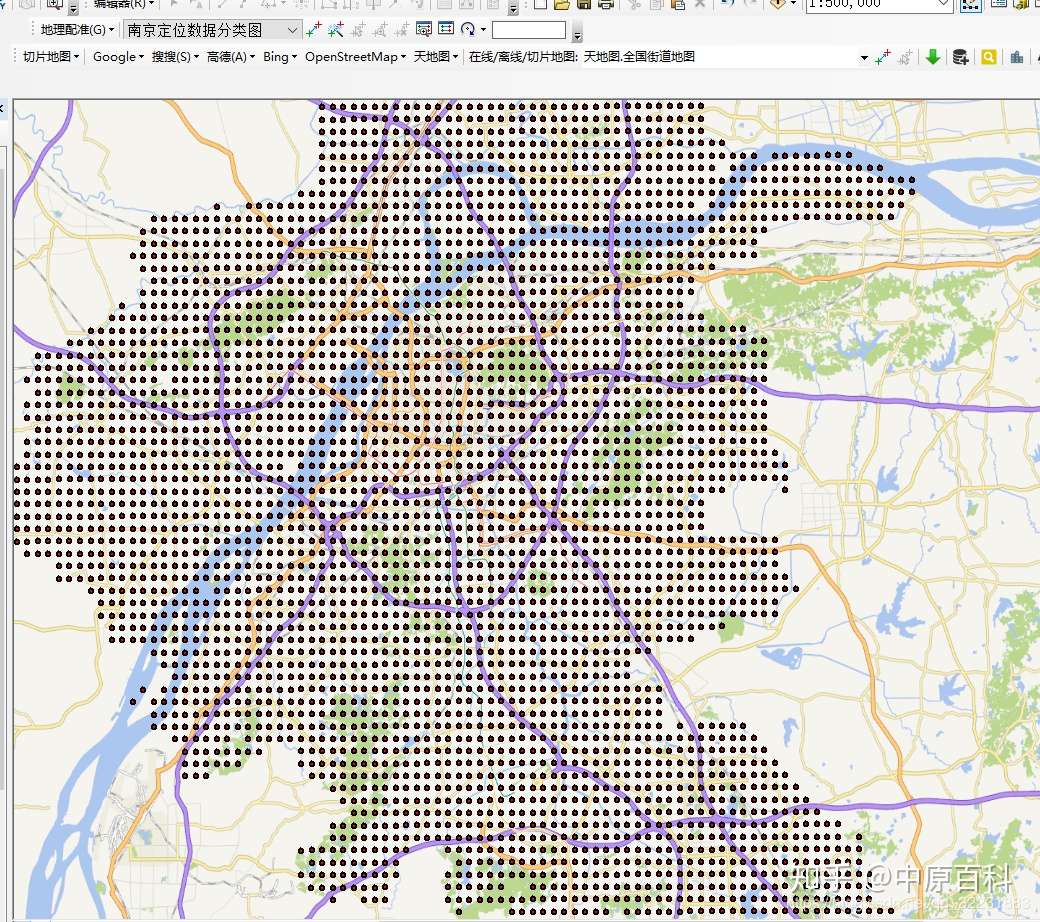
这样就得到了下图(南京包含在里面),这里的数据没有像上图那么排列完整密集是因为这只是一次定位数据的一个count而已,数据量很小,只是做演示用的。
方法二:从时间角度,这个就更简单了,爬一段时间就让你的程序停一段时间,这样的又可以稀释数据了。
if __name__ =='__main__':
while(1):
for i in range(4):
get_TecentData(4,i)
time.sleep(120)
总结:
需要注意的是该平台只能爬到当前数据,历史数据是爬不到的,所以如果有论文研究需要的童鞋还是看准时间赶紧爬吧,因为不知道这个接口啥时候就会被封了。(以前的接口是https://xingyun.map.qq.com/api/getpointbytime,最近改了,以前是每个五分钟可以爬一次数据,现在变成了可以每隔几秒钟爬一次了)
2019.7.18更新:
当大家开始运行程序的时候也会或多或少遇到很多报错,这里我也总结了下常见报错的解决方法:python爬取腾讯位置大数据遇到的各种报错问题解决方案汇